
Yesterday, when I posted some quick analysis and thoughts on the Wuhan Coronavirus, I thought I might see some extra traffic given the extensive news coverage. Given that I ended up with over 30 times my usual page views, it seems there is some interest to warrant a little more analysis!
I think the big question on everyone’s mind right now is - just how bad is this thing going to be? We’ve already seen some impact to the financial markets but how bad of an outcome has been priced in?
Defining what is “bad” is pretty much a function of how many people get infected and how many people die. Again, based on my comments yesterday, I believe it is too early to speculate on the death rate and we should hope it continues to drive lower and not higher like SARS did. Thankfully, way-too-early indications seems to point to lower.
The question then is, how many people will get infected? Well, I did some math things and put together a simple forecast that reflects my own guess for the next few days:
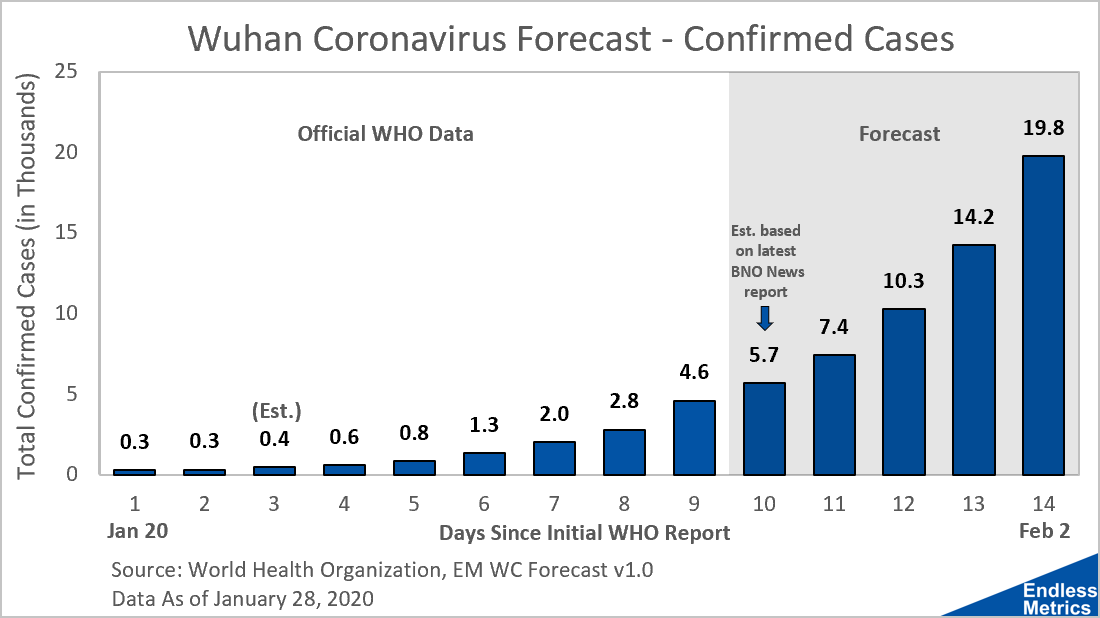
If you are nerd like me, then the basic shape of this function should be pretty obvious as exponential. I decided to use a simple exponential function as the foundation of this forecast because it’s:
Simple
Fitting the data well (so far)
Isn’t a more complicated model like a SIR model (which people with PhDs and a lifetime of experience would probably laugh at me for calling it “complicated”)
Suitable to my relatively light background and experience in biological math modeling (it’s important to stay conservative and humble!)
I estimated the model’s base parameters based on their relationship to various cuts of the data so far and their fit to the number of cases we already have seen. I added some variability to the parameters and then ran 100,000 simulated forecasts and took the average to create the chart above.
I also used some personal judgement to guide the forecast when estimating the parameters. So, it reflects personal opinion as well. Some purists would scoff at that but, given the short time frame and the immediate frequency of new data coming in to validate the forecast accuracy or inaccuracy, I’m really not too worried about.
Over the years, I’ve done a lot of forecasts for various endeavors. Personally, I think forecasting is impossible and everyone is bound to get things wrong. But I continue to do it because, when done properly, it is a valuable process to quantify speculation and clearly define opinion.
A forecast is a guess. Some guesses are better than others. If we are academically honest and don’t keep too big of an ego about things and recognize that we will all inevitably be wrong, it can provide a powerful benchmark as data rolls in. If someone is willing to clearly define their forecast and own up to the outcome right or wrong, I find that much more helpful than people who just want to extrapolate in vague terms that cannot be measured in any way and claim to have known what would happen all along after the fact.
In this case, I have created a valuable tool for myself because I have pinned down an exact estimate of my opinion versus holding a thousand different opinions and potential numbers of the future in my subconscious and exacerbating hindsight bias. As new data comes in, I have a benchmark to measure against. Will new cases come more quickly than expected (hopefully not) or start to taper?
I am curious to see how the next few days develop and continue to hope for those affected to get well and those exposed to stay healthy. With new data, I’ll make some tweaks to the forecast and in the next few posts follow up with my thinking and plans for next phase of the forecast (because it certainly can’t stay exponential forever).
If you aren’t already subscribed to this newsletter and would like to directly receive updates in your inbox, feel free to sign up below to help support ongoing content!